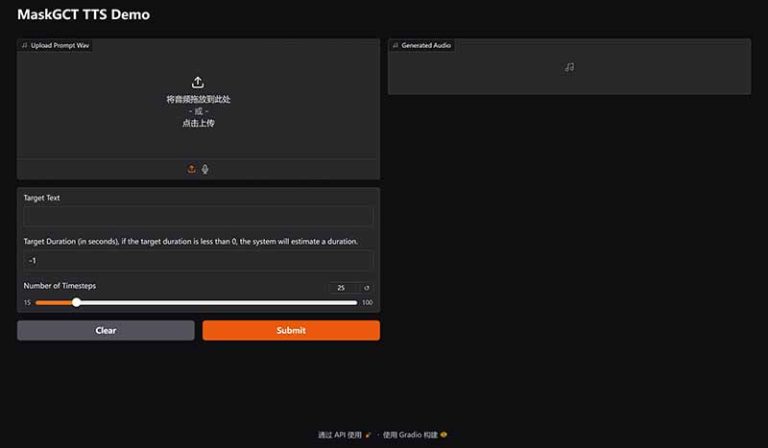
本地部署解压直接运行 无广告纯绿色
MaskGCT是由趣丸科技(FunnyAI)与香港中文大学(深圳)联合研发的开源语音大模型,基于掩码生成编解码器 Transformer(Masked Generative Codec Transformer) 技术构建。其官方数据格式设计围绕多语言语音合成、声音克隆及语音控制等核心能力,结合非自回归生成范式与语音表征解耦编码技术,实现高效且高质量的语音生成。以下是关键数据格式与技术要点的系统梳理:
⚙️核心架构与处理流程
MaskGCT采用两阶段生成流程,通过解耦语义与声学表示提升可控性与效率:
-
文本 → 语义标记(Text-to-Semantic)
-
输入:文本序列(UTF-8编码,支持中、英、日、韩、法、德6种语言)16。
-
输出:语义标记序列,源自语音自监督模型(SSL)的离散化表示(如W2v-BERT 2.0第17层特征)58。
-
技术:非自回归掩码Transformer,随机掩码部分标记并基于上下文预测,无需音素对齐25。
-
-
语义标记 → 声学标记(Semantic-to-Acoustic)
-
输入:语义标记序列。
-
输出:多层声学标记(12层残差向量量化/RVQ),用于重建波形58。
-
编解码器:
-
语义编解码器:VQ-VAE模型,最小化信息损失5。
-
声学编解码器:Vocos架构,支持24kHz采样率波形重建58。
-
-
📥输入/输出格式规范
输入格式:
-
文本输入:UTF-8字符串,支持多语言混合文本16。
-
参考语音(克隆/编辑场景):
-
格式:PCM/WAV(24kHz采样率)5。
-
时长:≥3秒(推荐5秒)47。
-
内容:需包含目标音色、韵律或情感特征2。
-
输出格式:
-
语音波形:24kHz采样率WAV文件5。
-
可控参数:
-
时长(总长度因子0.8–1.2)5。
-
语速(词/分钟)、情感标签(如开心/悲伤)12。
-
跨语言转换(保留原音色生成目标语言语音)6。
-
🧩内部数据表示格式
| 组件 | 数据表示 | 技术实现 |
|---|---|---|
| 语义标记 | 离散ID序列(VQ-VAE量化) | 基于W2v-BERT 2.0特征训练,减少音调语言信息损失58 |
| 声学标记 | 12层RVQ(残差向量量化)标记 | 多层结构保留高频细节;Vocos解码器高效重建波形58 |
| 掩码预测序列 | 动态掩码位置标记(训练时随机掩码,推理时按需生成) | 双向Transformer+自适应RMSNorm58 |
🧠模型部署与规格
预训练模型版本(Hugging Face开源)56:
| 版本 | 参数量 | 支持任务 | 下载地址 |
|---|---|---|---|
| Base | 300M | 基础TTS、语音克隆 | amphion/maskgct-base |
| Large | 700M | 跨语言合成、情感控制 | amphion/maskgct-large |
| X-Large | 1.3B | 高保真影视配音、唇音同步 | amphion/maskgct-xlarge |
📚训练数据基础
-
数据集:Emilia(10万小时多语言语音)34。
-
语言:中、英、日、韩、法、德。
-
内容:涵盖朗读、对话、情感语音等场景。
-
质量:人工筛选高保真样本,信噪比>30dB46。
-
-
预处理:
-
语音分段(静音切除+VAD)。
-
文本标准化(数字/符号转写)5。
-
⚡推理配置参数
| 参数 | 范围 | 功能 |
|---|---|---|
temperature |
0.2–1.0 | 控制生成多样性(低→稳定;高→创意) |
top_p |
0.8–0.95 | 核采样阈值,过滤低概率标记 |
length_factor |
0.8–1.2 | 调整生成语音总时长 |
semantic_prefix |
10–50标记 | 参考语音的语义前缀(克隆场景关键)5 |
💡应用场景与数据流示例
-
短剧出海(趣丸千音平台)47:
输入视频 → 分离音频 → 文本翻译 → MaskGCT生成目标语言语音 → 唇音同步合成。 -
声音克隆:
参考音频(5s)→ 提取语义标记 → 生成新文本对应语音(保留音色/情感)